QCon北京2018 Apache Pulsar——實現實時數據處理中消息、計算與存儲的統一
在QCon北京2018大會上,Apache Pulsar作為一個新興的分布式消息流平臺,吸引了眾多開發者與架構師的關注。其核心愿景在于解決現代數據驅動型應用面臨的復雜挑戰——如何高效、統一地處理實時數據流,并彌合消息傳遞、實時計算與持久化存儲之間的鴻溝。Pulsar的設計哲學并非簡單替代現有的消息隊列或流處理系統,而是旨在提供一個融合性的平臺,將消息、計算和存儲三層架構統一起來,構建下一代的數據處理和存儲服務。
傳統架構中,消息系統(如Kafka、RabbitMQ)、計算框架(如Flink、Spark Streaming)與存儲系統(如HDFS、數據庫)往往是分離的。這種分離導致了數據冗余、運維復雜、端到端延遲增加以及一致性保障困難等問題。Apache Pulsar通過其獨特的架構設計,試圖從根本上改變這一局面。
分層架構與統一模型
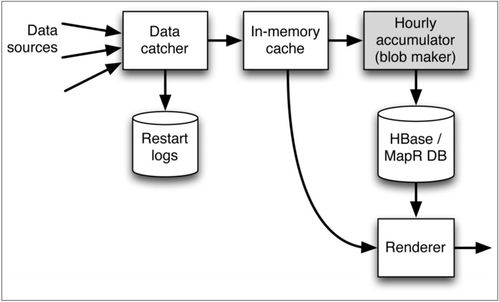
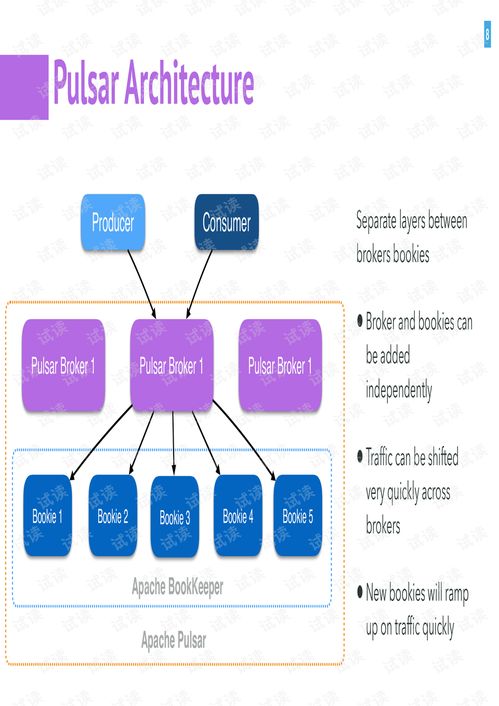
Pulsar的核心創新之一是其分層的系統架構。它將服務層(Broker) 與存儲層(BookKeeper) 分離。Broker集群是無狀態的,專門負責消息的傳遞、路由和輕量級處理;而持久化存儲職責則由Apache BookKeeper負責,這是一個專為高吞吐、低延遲持久化日志數據而設計的分布式存儲系統。這種分離帶來了極佳的彈性擴展能力——計算(Broker)和存儲(BookKeeper)可以獨立擴展,互不影響。
在此架構基礎上,Pulsar實現了消息、計算和存儲的統一抽象。對于應用而言,Pulsar提供了一個統一的“流”模型。無論是作為消息隊列(Queue)、發布訂閱(Pub-Sub)還是更高級的流處理(Streaming)場景,都可以通過同一套API和主題(Topic)語義來操作。這意味著開發者無需在不同的系統間進行繁瑣的數據搬運和格式轉換,數據從攝入、處理到存儲,可以在Pulsar內部高效流轉。
統一的數據處理服務
Pulsar Functions 是Pulsar實現“計算統一”的關鍵組件。它是一個輕量級的計算框架,允許用戶以簡單的函數形式(Java、Python、Go等)直接在Pulsar集群上對數據流進行處理。這些函數可以消費來自一個或多個主題的消息,進行處理、轉換、聚合后,將結果寫入另一個主題。Pulsar Functions 的引入,使得一些簡單的ETL、實時聚合或事件響應邏輯無需引入龐大的外部流處理引擎,直接在消息系統內部完成,極大地簡化了架構,降低了延遲和運維成本。
對于更復雜的流處理任務,Pulsar通過原生的Pulsar IO 連接器框架和與主流計算引擎(如Apache Flink、Apache Spark、Apache Storm)的深度集成,無縫地將數據流橋接到外部計算框架中。Pulsar的“無限”數據保留策略(得益于BookKeeper的持久化能力)意味著歷史數據可以直接在存儲層進行訪問,為批流一體(如Apache Flink的批流統一處理)和回溯分析提供了便利,進一步模糊了實時與離線處理的邊界。
統一的存儲服務
在存儲層面,Apache BookKeeper 提供了堅實、可擴展的基石。它將數據以日志段(Ledger)的形式存儲在多個存儲節點(Bookie)上,保證了數據的強一致性和高可用性。Pulsar利用這一特性,實現了:
- 無限的積壓(Backlog):消息可以被持久化存儲任意長時間,而不像傳統消息系統通常受內存或本地磁盤限制。
- 即時擴展與均衡:由于存儲與計算分離,當需要增加存儲容量時,只需添加新的Bookie節點,數據會自動進行再平衡,無需遷移整個Broker。
- 分層存儲(Tiered Storage):Pulsar支持將較舊的數據從BookKeeper卸載到更廉價的存儲系統(如AWS S3、Google Cloud Storage或HDFS)中,而對客戶端完全透明。這實現了冷熱數據的自動分層管理,在保證低延遲訪問熱數據的大幅降低了海量歷史數據的存儲成本,真正統一了在線和近線存儲。
與展望
在QCon北京2018的分享中,Apache Pulsar所展示的“消息、計算和存儲的統一”理念,指向了云原生時代數據處理架構的未來。它通過解耦、分層和原生集成的設計,提供了一個高性能、高彈性、易運維的一站式平臺,用于構建實時數據管道和流式應用。
采用Pulsar意味著可以減少技術棧的復雜性,降低多系統間數據同步的延遲與風險,并能夠靈活應對業務規模的增長。隨著Pulsar生態的持續完善(如事務支持、Schema Registry的強化、更多連接器的開發),它正日益成為構建統一數據處理和存儲服務的強力候選,為從物聯網、實時分析到金融交易等廣泛場景提供堅實的數據基礎設施。
如若轉載,請注明出處:http://www.kanpic.net/product/52.html
更新時間:2026-01-07 05:27:51